Introduction
Elasticsearch is an open-source search solution which is quite popular for logs analysis. It allows data from various different sources to be available and searchable at a centralized location.
In this post, we will see how to ingest logs from S3 into Elasticsearch using AWS Lambda.
Architecture
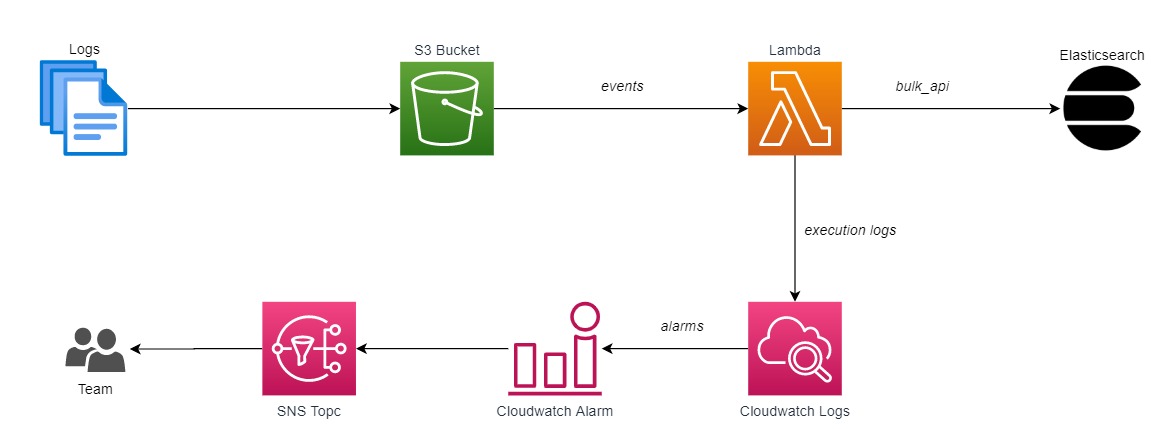
The stack will look like the following once launched. Logs are written to the S3 bucket. Our ingestion lambda is then triggered based on these events. The logs for this Lambda is written to AWS Cloudwatch, and alarms are also created to notify the relevant team if there are failures. Once the Lambda is able to read and process the log file from S3, it pushes them to the Elasticsearch cluster using the /bulk_api.
Ingestion
Elasticsearch offers a lot of options to ingest data - Beats, Logstash, language specific clients and a generic REST API.
The REST API offers 2 distinct endpoints for indexing data - single document or bulk. The single document API is useful to index a small number of documents. In case, the number of documents to index is large it is often benefitial to use the bulk API.
For the purpose of this Lambda, we will use the _bulk REST API to index the data.
Bulk Ingest REST API
The bulk API for ingesting docs into Elasticsearch offers a couple of subtle variations as follows -
1POST /_bulk
2{ "index" : { "_index" : "test1" } }
3{ _document1_ }
4{ _document2_ }
5{ "index" : { "_index" : "test1" } }
6{ _document3_ }
OR
1POST /index/_doc/_bulk
2{ "index" : {}}
3{ _document1_ }
4{ _document2_ }
5{ _document3_ }
Do note, that the document which is submitted as part of the bulk API is not a valid json. Each line of the document needs to be a valid json.
S3 Logs
The logs being pushed into S3 need to conform to the following format -
- Valid json string on each new line
- S3 path -
s3://bucket/service/date/logfile-sequence.log
Lambda
The Lambda is triggered on every S3 put object event. It then reads the contents of the file and prepares a bulk ingestion doc as pecified in the section above.
A new index is created daily during ingestion. Index name pattern is service-date. Example - httpd-2020.01.01
Ingest Pipelines
As I wrote in an earlier post, ingest pipelines are quite easy to setup. They can step-in if you have modest data transformation needs, and do not want (or need) a full blown logstash setup. Pipeline can be specified as a query parameter during ingestion.
1POST /index/_bulk?pipeline=master_pipeline
2{ "index" : {}}
3{ _document1_ }
4{ _document2_ }
5{ _document3_ }
Source code
Once the repo is cloned, you can run the below steps before deploying the stack.
Create and activate virtual environment
1$ python3 -m venv env 2$ source env/bin/activateInstall dependencies
1$ (env) pip install -r requirements.txtFormat, lint, run tests, check coverage reports etc.
1$ (env) black src/*.py 2$ (env) flake8 3$ (env) pytest 4$ (env) coverage run -m pytest 5$ (env) coverage html

Deploying the Solution
We will use Serverless framework to deploy all the resources as depicted in the architecture diagram above. Modify configs as per your environment - ES base url, account number etc, and then follow the steps below to create this stack.
Export the AWS credentials as environment variables. Either access/secret keys or the aws cli profile
Deploy/Update the service to AWS
1$ sls deployTo cleanup and remove the resources, just run
1$ sls remove
Conclusion
That’s it!
This was a simple function to index documents to an Elasticsearch cluster. Feel free to customize the function to work in your environment.
Hope this post proves useful. 👍
Note: Code mentioned above is here