AWS DynamoDB sandbox
Scope
- standard tables - regional
- global tables - global (cross-region replication)
Table classes
- Standard
- Standard-IA
- infrequently accessed data. Similar to S3 storage classes?
- consider standard-IA if the storage cost > 50% throughput cost (read/write units)
Capacity Modes
- on-demand
- provisioned throughput
Cache
DAX, DAX cluster - Dynamodb accelerator provisioned in a VPC.
providing in-memory cache, and increases performance by 10x
Autoscaling
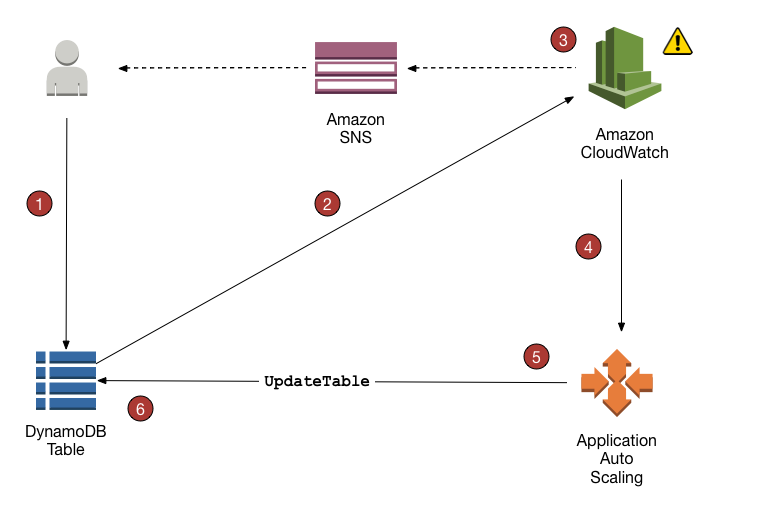
Use auto scaling policy for [[AWS AutoScaling]] to adjust the provisioned read/write throughput to meet demand. Target tracking algo based on specified target utilization or based on schedule. If a table uses Global secondary index, ensure to enable the same auto scaling properties on that as well.
Reservation
Cost savings compared to on-demand prices if you commit to an hourly use rate. Good option to reduce cost if the traffic pattern is predictable, well-understood and builds up gradually.
Performance
| Read | Size | Read Request Unit |
|---|---|---|
| strongly consistent | <= 4 KB | 1 |
| eventually consistent | <= 4 KB | 1.5 |
| transactional ACID | <= 4 KB | 2 |
| Write | Size | Write Request Unit |
|---|---|---|
| ? | <= 1 KB | 1 |
| transactional ACID | <= 1 KB | 2 |
Issue
Performance issues when scaling are usually caused by selecting inefficient partition keys that do not load the partitions equally and therefore do not spread write or read load properly across the partitions. When this happens, it is called “hot keys” or “hot partitions.” Evaluate partition keys to understand if this is causing issues.
Fine grained access
Provide access to principals on specific attributes or keys
https://aws.amazon.com/blogs/aws/fine-grained-access-control-for-amazon-dynamodb/ - Using IAM policy
Kinesis Data Streams for DynamoDB
Captures and stores information about data changes in a particular table. These records are held for upto 1 year.
Duplicate records might appear in stream,
DynamoDB streams
Captures and stores information about data changes in a particular table. These records are held for 24 hours before being automatically removed.
NO duplicate records appear in this stream.
It is very similar to Kinesis Data Streams, so you can use the KCL (Kinesis Client Library) to process streams. Using Streams Kinesis Adapter allows interacting with the low level streams api by using KCL.
graph LR a(My App) --> k1(KCL) --> k2(Kinesis Adapter) k3(Kinesis Adapter) --> s1(AWS SDK) --> s2(Streams API) --> s(Streams)
Streams can trigger synchronous lambda functions as new records are added to it. This lambda can be used to perform actions based on a record change in the table. Maybe save before/after to S3 to create an audit trail.